
近日,实验室成员作为第一作者的2篇论文被CCF-A类会议 ACM Multimedia (ACM MM) 2024 接收。
1. 论文题目:Label Text-aided Hierarchical Semantics Mining for Panoramic Activity Recognition
作者:刘天山,Lam Kin-Man,鲍秉坤
通讯作者:鲍秉坤
全景行为识别旨在同时识别多粒度的人体行为,包括个体动作、社群活动和全局行为,是人群场景理解中一项具有挑战性的任务。以往的研究工作往往只从视频输入中捕捉跨粒度的行为语义关系,从而忽略了标签文本空间中固有的层次化语义。为此,本文提出了一个标签文本辅助下的层次化语义挖掘框架,该框架通过学习对齐视觉内容和标签文本之间的层次化语义来探索多层次的跨模态关联。具体而言,通过构造一个分层编码器,将视觉和文本输入编码为不同粒度的语义对齐表征;为了充分利用编码器学习到的跨模态语义对应关系,进一步设计了分层解码器,用以逐步将低层级表征与高层级上下文知识集成,以实现由粗到细的动作或行为识别。在公开的JRDB-PAR基准上的大量实验结果验证了所提出框架相较于现有方法的优越性。
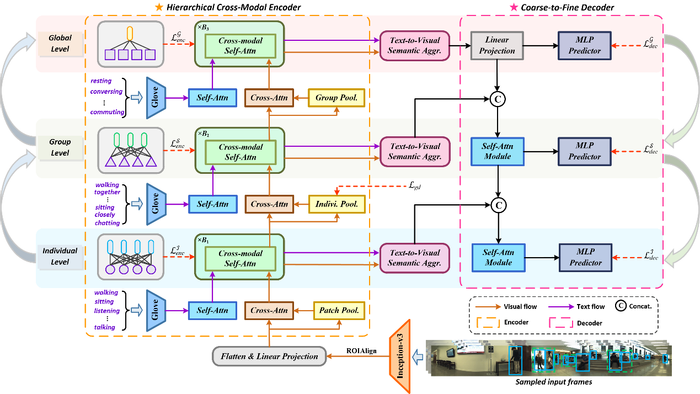
论文方法框图
2.论文题目:CoIn: A Lightweight and Effective Framework for Story Visualization and Continuation
作者:陶明,鲍秉坤,唐浩,王耀威,徐常胜
通讯作者:鲍秉坤
故事可视化旨在基于多句故事生成逼真且连贯的图像序列。然而,当前的方法在实现高质量故事图像生成的同时,面临着保持轻量级模型和快速生成速度的挑战。主要问题源于现有的两个框架。独立框架优先考虑速度,但牺牲了图像质量,采用非协作的图像生成过程和基于GAN的基本学习。自回归框架则通过自回归方式修改大型预训练文本到图像模型,并添加历史模块,导致模型体积庞大、资源密集型要求高,生成速度较慢。
为了解决这些问题,论文提出了一个轻量级且高效的框架,即CoIn (Contextualize and Interchange)。具体而言,引入了一个上下文感知故事生成器,用于预测每个图像生成器的共享上下文语义。此外,提出了一个故事内交换模块,允许每个图像生成器与其他图像生成器交换视觉信息。同时,将DINOv2纳入故事和图像鉴别器中,以更准确地评估故事图像质量。大量实验表明,CoIn框架在保持独立框架的模型大小和生成速度的同时,实现了优良的故事图像质量。
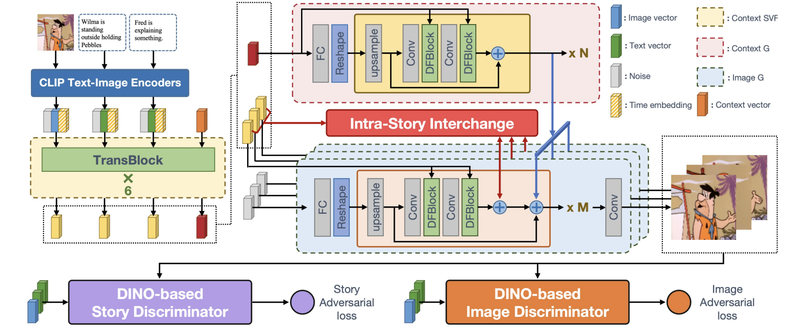
论文方法框图
(撰稿:刘天山 陶明 审核:贾耕云)
地址:江苏省南京市栖霞区仙林大学城文苑路9号(南京邮电大学仙林校区)计算机学科楼
电话:13813992640(贾老师)
邮箱:bingkunbao@njupt.edu.cn(鲍老师)