
近日,MCC实验室3篇论文被CCF A类学术会议IJCAI2025(International Joint Conference on Artificial Intelligence)接收。
1. 论文题目:DToMA: Training-free Dynamic Token MAnipulation for Long Video Understanding
作者:袁博闻,游思思,鲍秉坤
通讯作者:游思思
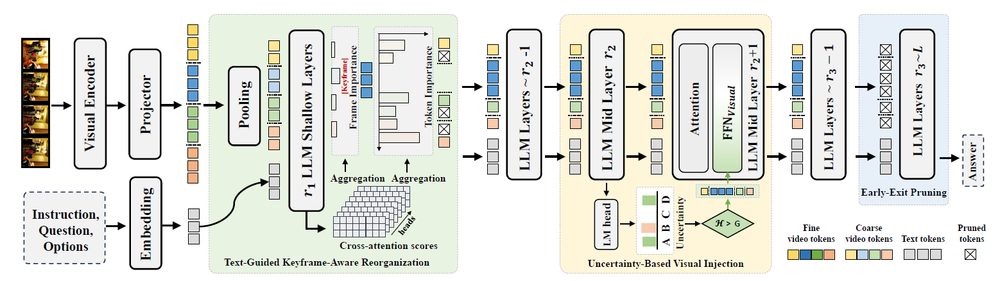
在长视频理解任务中,视频大语言模型通常需要数千个视觉令牌,计算成本高昂,而视觉令牌的使用效率低下进一步加剧了这一问题。尽管现有的令牌缩减和视频表示方法在一定程度上提升了处理效率,但往往以牺牲模型的理解能力为代价。本文针对这一矛盾,从多选视频问答任务出发,分析了视频大语言模型的推理过程,识别出三个依次递进的推理阶段——浅层、中层和深层阶段,这些阶段与人类的认知处理机制高度相似。通过深入分析,我们发现每个阶段均存在特定的低效问题:浅层阶段模型倾向于记忆所有视频细节而缺乏重点筛选;中层阶段未能对不确定内容进行动态回看;深层阶段则在已具备足够置信度的情况下仍持续处理视觉信息。为解决上述问题,我们提出了一种无需训练的动态令牌操作方法DToMA,其设计灵感来源于人类在不同认知阶段的调节机制。该方法包含三个核心模块:1)文本引导的关键帧感知重组,以优先提取关键帧并减少冗余;2)基于不确定性的视觉内容回注,实现对关键信息的动态再审视;3)早停剪枝机制,在模型置信度足够时提前终止视觉令牌处理。在六个长视频理解基准数据集上的实验结果表明,DToMA在提升处理效率的同时保持甚至增强了模型的理解能力,优于当前最先进的方法,并可良好泛化至三种不同架构和规模的视频大语言模型中。
项目地址:https://github.com/yuanrr/DToMA
2. 论文题目:SCVBench: A Benchmark with multi-turn dialogues for Story-Centric Video Understanding
作者:游思思,袁博闻,鲍秉坤
通讯作者:鲍秉坤
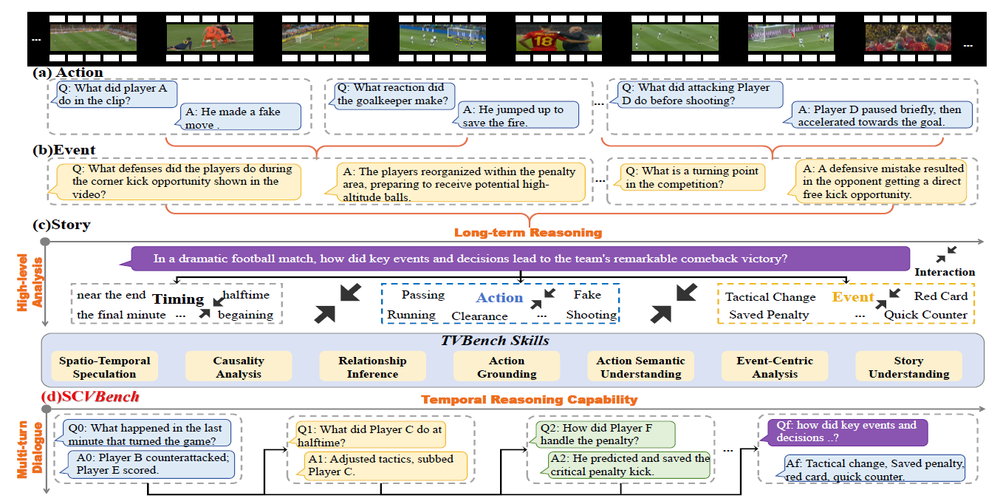
视频理解旨在使机器能够从三个层次——动作、事件和故事——解读视觉内容。然而,现有模型在高层次的长期故事理解方面存在局限性,主要原因包括:(1)对时间信息的过度简化处理,以及(2)由以动作/事件为中心的数据集带来的训练偏差。为解决这些问题,我们提出了SCVBench,一个面向故事中心的视频理解新基准。SCVBench通过将事件排序任务分解为多个子问题,并最终引导至一个核心问题的方式,来评估视觉语言模型在历史对话探索中的表现。我们从925个视频中收集了1,253个最终问题和6,027对子问题,构建了连续的多轮对话数据集。实验结果表明,尽管闭源模型GPT-4o在该任务上表现最佳,但大多数开源的多模态大模型在故事理解方面仍面临较大挑战。此外,我们提出的StoryCoT模型在SCVBench上显著优于现有的开源多模态大模型,展现出更强的时序推理与理解能力。我们的SCVBench通过系统评估多模态大模型在时间建模和语义理解方面的能力,推动了故事级视频理解的研究进展。
项目地址:https://github.com/yuanrr/SCVBench
3. 论文题目:Graph Prompts: Adapting Video Graph for Video Question Answering
作者:李一鸣,杨小汕,鲍秉坤,徐常胜
通讯作者:鲍秉坤
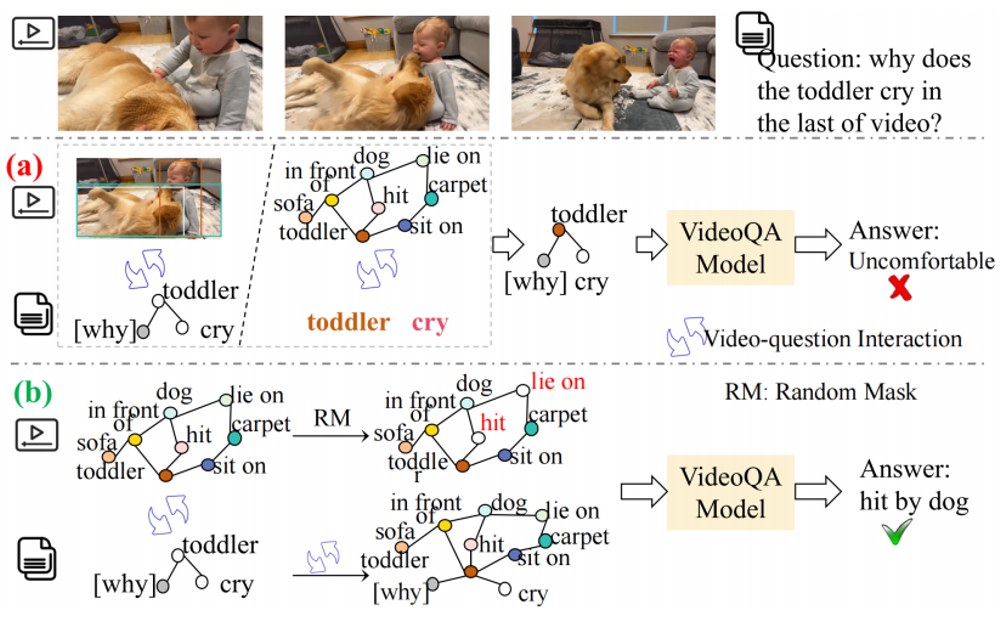
由于视频的动态特性,对时间信息的感知与推理显然是视频问答(VideoQA)的核心焦点。近年来,若干方法通过图结构视频表征探索了关系级时间建模。然而,这些方法严重依赖问题文本,因此难以对问题中未明确提及的视频内容进行感知与推理。为解决上述挑战,我们提出基于图提示的视频问答方法(GP-VQA),其采用基于视频的图结构以增强视频理解能力。所提出的GP-VQA包含预训练与提示调优两个阶段:在预训练阶段,我们定义了前置任务——要求GP-VQA对视频图中随机掩码的节点或边进行推理,从而促使其学习基于视频引导信息的推理能力;在提示调优阶段,我们将文本问题组织为问题图,并实现从视频图到问题图的消息传递,进而将视频图补全的推理能力迁移至视频问答任务中。在多个数据集上的大量实验验证了GP-VQA的优异性能。
撰稿:袁博闻,李一鸣 审核:贾耕云
地址:江苏省南京市栖霞区仙林大学城文苑路9号(南京邮电大学仙林校区)计算机学科楼
电话:13813992640(贾老师)
邮箱:bingkunbao@njupt.edu.cn(鲍老师)