
近日,实验室4篇论文被CCF A类学术会议ACM MM 2025 (ACM International Conference on Multimedia)接收。
1. 论文题目:DMC3:Dual-Modal Counterfactual Contrastive Construction for Egocentric Video Question Answering
作者:邹佳怡,陈超凡,鲍秉坤,徐常胜
通讯作者:鲍秉坤
第一视角视频问答任务存在两个关键的挑战。具体来说,由于第一视角视频关注人手与物体的交互,这就要求模型能够建模视觉交互的细粒度信息。此外,问题文本中包含许多事件的相关描述,这就要求模型能够理解文本里关于事件的上下文信息。而现有的方法大多通过预训练微调的方式设计一个通用的视觉语言大模型,没有关注到第一视角视频问答的特有挑战,从而导致了次优的性能。为了解决该任务的两个挑战,我们设计了一个双模态反事实构建对比学习框架。针对视觉模态,我们在核心区域挖掘模块通过设计交互区域选择的方法捕捉视频帧的交互区域,并把它们保留或者去除来生成事实样本和反事实样本作为视觉正负样本。针对文本模态,我们在事件描述重构模块通过对原来的样本进行同义词替换构建事实样本作为问题正样本;对原来的样本掩盖事件描述并变换时间顺序构建反事实样本作为问题负样本。然后,我们把原来的样本和正负样本分别输入到视频问答模型中得到对应的融合特征。最后,我们引入了对比损失,把原样本得到的融合特征与正样本特征距离拉近,与负样本特征距离拉远,从而促使原来的模型能够更加关注视频的交互部分与文本的事件描述,最终提高预测的准确率。我们的方法在两个第一视角视频问答数据集上都取得了最优的性能。

2. 论文题目:Retaining Temporal Semantics and Relation Topologies for Continual Weakly-Supervised Audio-Visual Video Parsing
作者:傅杰,鲍秉坤
通讯作者:鲍秉坤
弱监督视听视频解析任务因其采用标注成本低廉的学习范式而受到研究者们广泛关注,但是它们假设行为类别固定不变,因此难以应对新类行为持续涌现的实际场景。为了缓解上述问题,我们提出了一种持续弱监督视听视频解析(C-WSAVVP)任务,旨在探索一种类增量学习模式,仅利用视频级弱监督监督信号来学习可靠且能够实现新类持续泛化的视听行为定位模型。鉴于C-WSAVVP任务中视频的弱监督和多模态属性,不同于持续视听视频分类(C-AVVC),C-WSAVVP中存在的两个特殊且关键的挑战:(1)相比于C-AVVC中蒸馏视频级粗粒度行为语义便足以缓解模型对历史行为遗忘的问题,C-WSAVVP需要鉴别视频内更加细粒度的行为信息;(2)不同行为间通常存在语义关联,这一信息可以增强模型对相关联行为的准确定位,但如何提取并在持续泛化过程中保留这一信息?为了应对上述挑战,我们从语义原型学习的统一视角设计了基于语义原型的时序行为预测调制模块和类间关系拓扑保持模块,前者致力于挖掘行为语义原型来调制视频行为时序预测,以实现更加可靠的行为语义蒸馏;后者则关注保留视听模态内不同行为间的拓扑关系,以实现对关联行为的精准感知。最后,为了验证所提出的方法在C-WSAVVP任务上的合理性和有效性,我们重构了C-LLP数据集,充分的实验结果验证了我们所提出的方法的有效性和泛化能力。
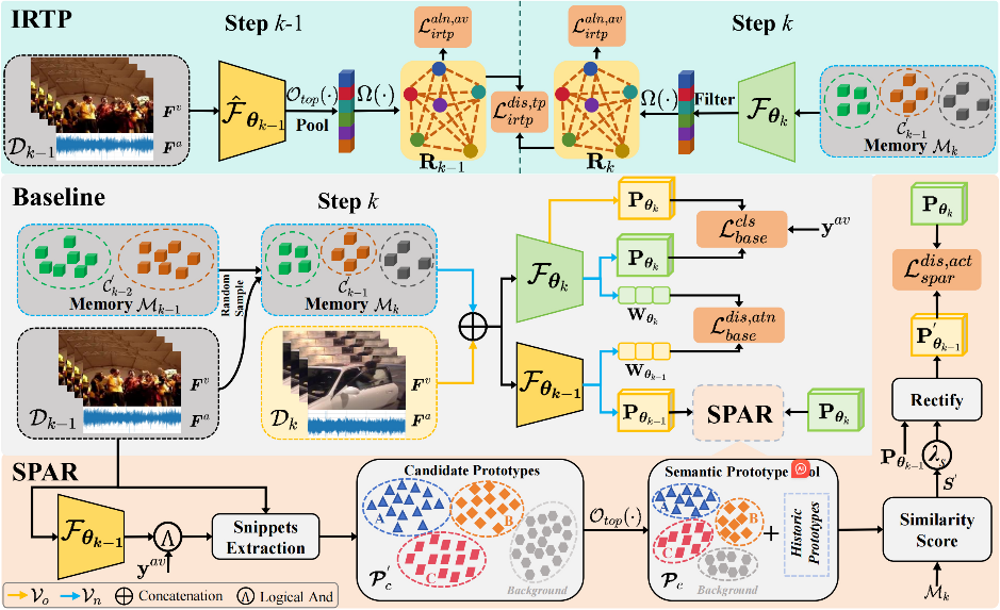
3. 论文题目:Gaussian: Dynamic Control with Discretized 3D View Modeling for Text-Driven 3D Gaussian Splatting Editing
作者: 盛业斐,王婕,陶明,鲍秉坤
通讯作者: 鲍秉坤
在文本驱动的3D场景编辑任务中,基于多视图渲染的方法已成为主流,通常来说,这些方法将3D表示渲染成多视图图像,并使用文本指令修改图像,尽管这些方法较为有效,但我们认为它们没有充分利用3D场景的空间特征信息,导致编辑效果不佳,为了验证我们的论点,我们对现有方法展开了深入分析,发现现有的方法在所有视图中固定相同的文本指令,并冻结了单视图编辑的预训练2D模型,进一步的分析实验表明,这种处理方式会导致3D场景视图建模不充分,并产生不一致的视觉伪影,为了解决该问题,我们提出了一种离散化的3D视图建模方法和一种基于扩散模型的多视图一致性编辑流程,用于文本驱动的3D高斯溅射编辑,其思想是通过有效地建模空间特征表达式和构建多视图一致的编辑流程来实现高质量的3D场景编辑,我们首先设计了码本构建方法,将连续的3D视图信息编码成离散的token嵌入,然后提出了标记嵌入来指导和微调基于扩散的图像编辑模型,并动态添加控制条件,从而构建多视图一致的编辑流程,最后构建了基准测试集3D-MagicBrush,为未来的3D编辑工作提供更多样化的评估场景,与现有方法相比,我们的方法在视觉效果和多视图一致性方面都实现了显著提升。
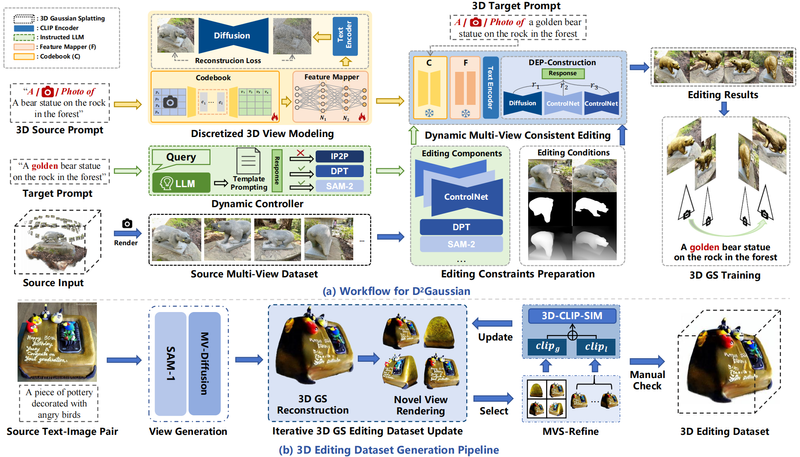
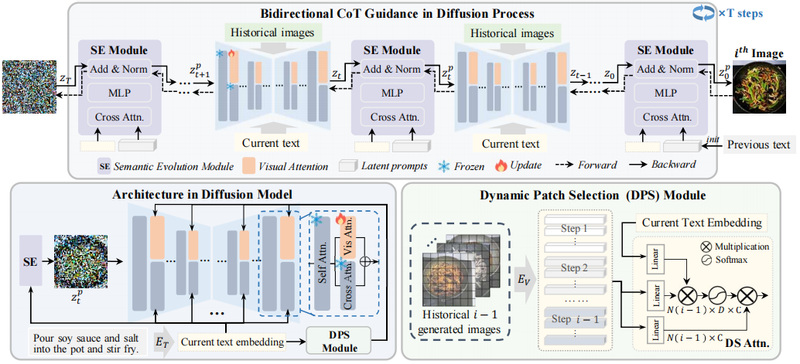
4. 论文题目:Chain-of-Cooking: Cooking Process Visualization via Bidirectional Chain-of-Thought Guidance
作者:徐梦玲,陶明,鲍秉坤
通讯作者:鲍秉坤
烹饪过程可视化是图像生成与食品分析交叉领域的一项前景广阔的任务,旨在为食谱的每个烹饪步骤生成对应图像。然而现有研究大多根据给定食谱生成最后的成品菜肴图像,在实现烹饪过程可视化时面临两大挑战:首先,食材外观在烹饪各阶段会发生多样变化,难以生成与特定步骤文本描述相匹配的正确食物外观,导致语义不一致;其次,当前烹饪步骤可能依赖于前序步骤的操作,保持图像序列的上下文连贯性至关重要。本研究提出基于扩散模型的烹饪过程可视化方法“烹饪链式生成”。为生成准确的食材外观,我们设计了动态图像分块选择模块,从先前生成的图像中检索与当前文本内容最相关的图像块。为了更好地利用每个扩散步骤中前文语义,语义演化模块建立了潜在提示与当前烹饪步骤之间的语义关联,并将其与扩散过程中的潜在特征相融合。随后,双向思维链引导机制通过可学习的潜在提示更新融合后的潜在特征,从而确保当前烹饪步骤与上一步骤保持连贯性。针对烹饪过程可视化数据匮乏的问题,本研究构建了名为CookViz的数据集,其中包含完整烹饪过程的中间图文对。定量与定性实验表明,本方法实现了序列连贯且语义一致的烹饪过程图像可视化。
撰稿:邹佳怡,傅杰,盛业斐,徐梦玲 审核:贾耕云
地址:江苏省南京市栖霞区仙林大学城文苑路9号(南京邮电大学仙林校区)计算机学科楼
电话:13813992640(贾老师)
邮箱:bingkunbao@njupt.edu.cn(鲍老师)